Tables from earlier joins are read in portions into the join buffer, and then their rows are used from the buffer to perform the join with the current table.
Using temporary
Query过程中构造一张临时表,常见order by,group by中。出现时性能可能不高
Using where
有where子句
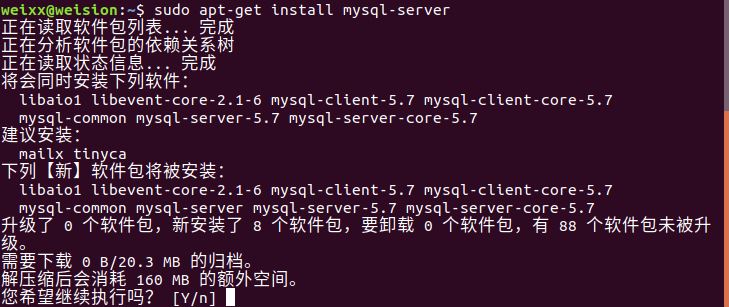
二. 实验
环境准备
CREATE DATABASE `gc` /*!40100 DEFAULT CHARACTER SET utf8 */;
use gc;
CREATE TABLE `emp` (
`emp_no` varchar(20) NOT NULL,
`emp_name` varchar(30) NOT NULL,
`age` int(11) DEFAULT NULL,
`dept` varchar(45) DEFAULT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into emp values ('MW00001','Oraman',30,'1');
insert into emp values ('MW00002','GC',25,'2');
insert into emp values ('MW00003','Tom Kyte',50,'1');
insert into emp values ('MW00004','Jack Ma',40,'3');
insert into emp values ('MW00005','James',33,'4');
CREATE TABLE `dept` (
`dept_no` varchar(45) NOT NULL,
`dept_name` varchar(30) NOT NULL,
`dept_header` varchar(20) DEFAULT NULL,
PRIMARY KEY (`dept_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into dept values ('1','DBA','MW00003');
insert into dept values ('2','DEV','MW00002');
insert into dept values ('3','BOD','MW00004');
insert into dept values ('4','Business','MW00005');