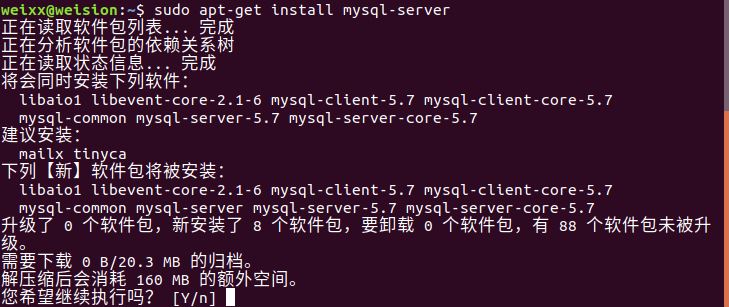
索引有很多,且按不同的分类方式,又有很多种分类。不同的数据库,对索引的支持情况也不尽相同。
声明:本人主要简单示例mysql中的单列索引、组合索引的创建与使用。
CREATE TABLE 表名(
字段名 数据类型 [完整性约束条件],
……,
[UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY
[索引名](字段名1 [(长度)] [ASC | DESC]) [USING 索引方法]
);
说明:
注:索引方法默认使用B+TREE。
单列索引(示例):
CREATE TABLE projectfile ( id INT AUTO_INCREMENT COMMENT '附件id', fileuploadercode VARCHAR(128) COMMENT '附件上传者code', projectid INT COMMENT '项目id;此列受project表中的id列约束', filename VARCHAR (512) COMMENT '附件名', fileurl VARCHAR (512) COMMENT '附件下载地址', filesize BIGINT COMMENT '附件大小,单位Byte', -- 主键本身也是一种索引(注:也可以在上面的创建字段时使该字段主键自增) PRIMARY KEY (id), -- 主外键约束(注:project表中的id字段约束了此表中的projectid字段) FOREIGN KEY (projectid) REFERENCES project (id), -- 给projectid字段创建了唯一索引(注:也可以在上面的创建字段时使用unique来创建唯一索引) UNIQUE INDEX (projectid), -- 给fileuploadercode字段创建普通索引 INDEX (fileuploadercode) -- 指定使用INNODB存储引擎(该引擎支持事务)、utf8字符编码) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT '项目附件表';注:这里只为示例如何创建索引,其他的合理性之类的先放一边。
组合索引(示例):
CREATE TABLE projectfile ( id INT AUTO_INCREMENT COMMENT '附件id', fileuploadercode VARCHAR(128) COMMENT '附件上传者code', projectid INT COMMENT '项目id;此列受project表中的id列约束', filename VARCHAR (512) COMMENT '附件名', fileurl VARCHAR (512) COMMENT '附件下载地址', filesize BIGINT COMMENT '附件大小,单位Byte', -- 主键本身也是一种索引(注:也可以在上面的创建字段时使该字段主键自增) PRIMARY KEY (id), -- 创建组合索引 INDEX (fileuploadercode,projectid) -- 指定使用INNODB存储引擎(该引擎支持事务)、utf8字符编码) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT '项目附件表';ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY [索引名] (字段名1 [(长度)] [ASC | DESC]) [USING 索引方法];
或
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX 索引名 ON 表名(字段名) [USING 索引方法];
示例一:
-- 假设建表时fileuploadercode字段没创建索引(注:同一个字段可以创建多个索引,但一般情况下意义不大)-- 给projectfile表中的fileuploadercode创建索引ALTER TABLE projectfile ADD UNIQUE INDEX (fileuploadercode);示例二:
ALTER TABLE projectfile ADD INDEX (fileuploadercode, projectid);示例三:
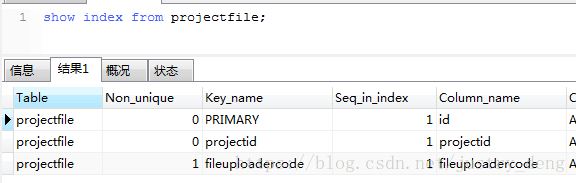
-- 将id列设置为主键ALTER TABLE index_demo ADD PRIMARY KEY(id) ;-- 将id列设置为自增ALTER TABLE index_demo MODIFY id INT auto_increment; show index from 表名;
提示:我们也可以直接使用工具查看
示例:
DROP INDEX 索引名 ON 表名
或
ALTER TABLE 表名 DROP INDEX 索引名
示例一:
drop index fileuploadercode1 on projectfile;示例二:
alter table projectfile drop index s2123;在select语句前加上EXPLAIN即可。
示例:
EXPLAIN SELECT * FROM `index_demo` ii WHERE ii.e_name = 'Jane';分析该SQL的性能为:

提示:我们也可以使用SQL工具查看,如:navicat中的“解释”选项即可查看。
说明:
id:SELECT识别符。这是SELECT的查询序列号。
select_type:SELECT类型。
table:表名
type:联接类型。是SQL性能的非常重要的一个指标,结果值从好到坏依次是:system > const > eq_ref > ref
> fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL。
一般来说,得保证查询至少达到range级别。
possible_keys:possible_keys列指出MySQL能使用哪个索引在该表中找到行。注意,该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。
key:key列显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
key_len:key_len列显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。注意通过key_len值我们可以确定MySQL将实际使用一个多部关键字的几个部分。
ref:ref列显示使用哪个列或常数与key一起从表中选择行。
rows:rows列显示MySQL认为它执行查询时必须检查的行数。
Extra:该列包含MySQL解决查询的详细信息。
给id加主键索引:

再分别给name、city、country、address加上普通索引:

注:以上五个索引都是单列索引。
只涉及到其中的一个字段时,都能使用到索引(以e_name为例):
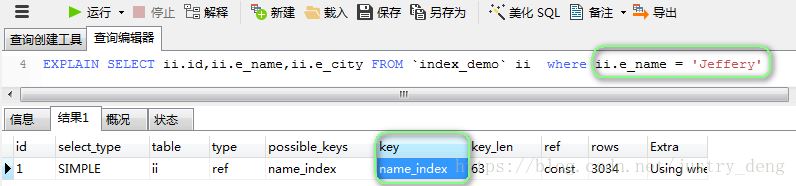
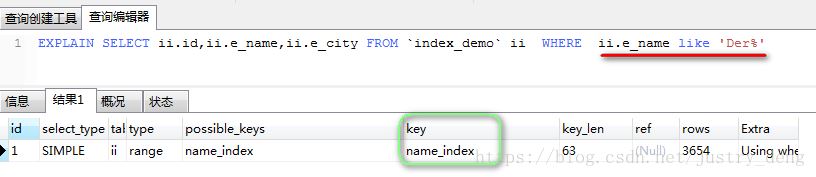
注:模糊查询时,%如果在前面,那么不会使用索引。
涉及到多个索引字段时,如果这些索引字段中,存在主键索引,那么只会使用该索引(即:MYSQL优化器会选出并先执行最“严”的索引):
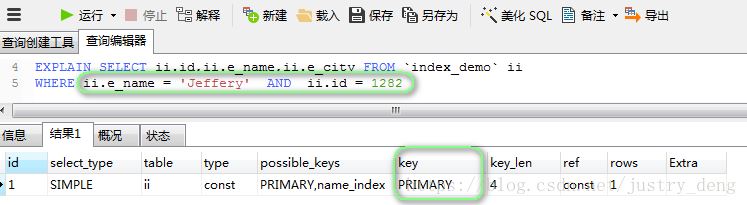
提示:possible_key中,只是SQL语句里涉及到的索引;key中才是实际上执行查询操作时使用到了的索引。
涉及到多个索引字段时,如果这些索引字段中,不存在主键索引的话,那么就会使用该使用的索引(注:如果通过其中的部分索引就能准确定位的话,那么其余的索引就不再被使用):


注:多个索引时,先使用哪个索引后使用哪个索引,是由MySQL的优化器经过一些列计算后作出的抉择。
当对索引字段进行 >, <,>=, <=,not in,between …… and ……,函数(索引字段),like模糊查询%在字段前时,不会使用该索引
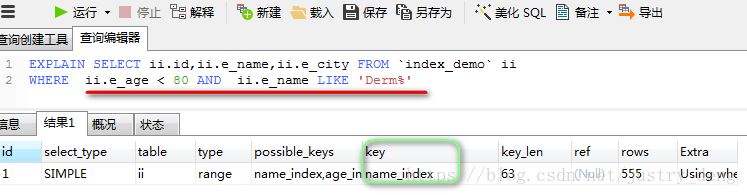
注:这里对e_age字段进行了 “<” ,所以实际查询时,并没有使用e_age的索引。
提示:在实际使用时,如果涉及到多列,我们一般都不会将这些列一 一创建为单列索引,而是将这些列创建为组合索引。
假设组合索引为:a,b,c的话;那么当SQL中对应有:a或a,b或a,b,c的时候,可称为完全满足最左原则;当SQL中查询条件对应只有a,c的时候,可称为部分满足最左原则;当SQL中没有a的时候,可称为不满足最左原则。
注:MySQL5.7开始,会自动优化,如:会把c,b,a优化为a,b,c使之完全遵循最左原则;会把c,a优化为a,c使之部
分遵循最左原则。即:SQL语句中的对应条件的先后顺序无关。

创建了组合索引:e_name,e_age,e_country,e_city。
完全满足最左原则:

注:与条件的先后无关(这是因为MYSQL5.7开始,对索引全排列有优化,会自动优化为按组合索引的顺序进行查询),
即:下面这样的话,也是会完整的走组合索引的:

部分满足最左原则:

注:此SQL中,只有e_name和e_country满足部分最左原则(e_name满足),所以到e_name字段时会走组合所以,但是
只会走到e_name那里,到e_country时就不会使用组合索引了。
不满足最左原则:
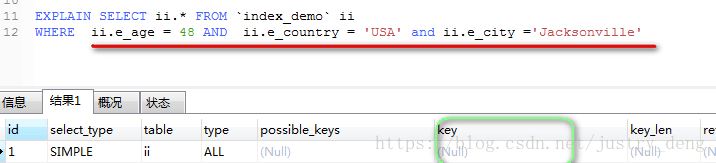
满足(部分满足)最左原则的字段里,有字段不满足“索引”自身的使用规范:
说明:如果SQL语句里的字段里,满足了最左原则,但是不满足“索引”自身的使用规范,那么组合索引走到这里之后,
不会再往下走了。
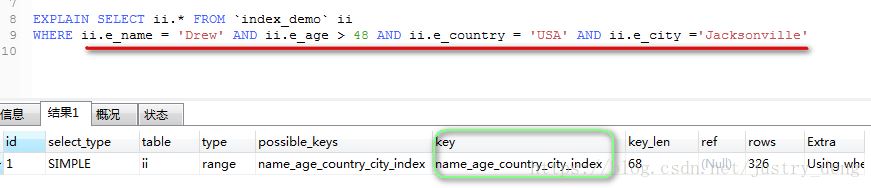
如图所示:由于e_age字段使用了“>”符号,不符合“索引”自身的使用规范,那么当“e_name”走完组合索引后,
走到“e_age”时,该字段及其后面的字段不会再走组合索引了。
聚集索引与非聚集索引:
每个InnoDB表具有一个特殊的索引称为聚簇索引(也叫聚集索引,聚类索引,簇集索引)。如果表上定义有主键,该主键索引就是聚簇索引。如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引。如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引。
表中的聚簇索引(clustered index )就是一级索引,除此之外,表上的其他非聚簇索引都是二级索引,又叫辅助索引(secondary indexes)。
回表:
当二级索引无法直接查询到(SQL中select需要的所有)列的数据时,会通过二级索引查询到聚簇索引(即:一级索引)后,再根据(聚集索引)查询到(二级索引中无法提供)的数据,这种通过二级索引查询出一级索引,再通过一级索引查询(二级索引中无法提供的)数据的过程,就叫做回表。
如,现有表:
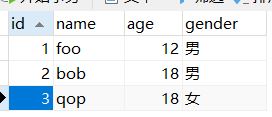
id是主键,其余三个字段组成联合索引:

当不需要进行回表时,即便我们的SQL不满足组合索引最左原则,也会走组合索引的,如:

这里where后直接是gender时, 是不遵循组合索引的最左原则的,但是查询计划显示使用了索引的。这是因为: 对这张表进行select *,相当于进行select id,name,age,gender,其中,id是主键(一级索引),name、age、gender是组合索引(二级索引),这里查询时,能直接从索引中拿到想要查询的所有列的数据,是不需要回表查询的,所以这里哪怕sql写法上不遵循最左原则,但是仍然是会走索引的。
如果这个时候,我们加一个普通的motto字段:

使用相同的SQL进行查询,可看到:

此时进行select *,相当于进行select id,name,age,gender,motto,其中motto字段是从索引(一级索引、二级索引)里面获取不到数据的,是肯定需要回表的。而查询条件又不遵循最左原则,所以不会走组合索引。
注:其它情况下,只有(完全或部分)遵循了最左原则,才会走组合索引。
新闻热点





疑难解答