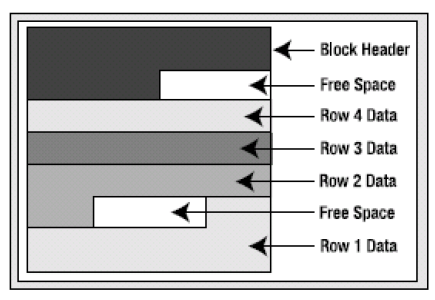
一:首先介绍一下索引聚簇表的工作原理:
聚簇是指:如果一组表有一些共同的列,则将这样一组表存储在相同的数据库块中;聚簇还表示把相关的数据存储在同一个块上。利用聚簇,一个块可能包含多个表的数据。概念上就是如果两个或多个表经常做链接操作,那么可以把需要的数据预先存储在一起。聚簇还可以用于单个表,可以按某个列将数据分组存储。
更加简单的说,比如说,EMP表和DEPT表,这两个表存储在不同的segment中,甚至有可能存储在不同的TABLESPACE中,因此,他们的数据一定不会在同一个BLOCK里。而我们有会经常对这两个表做关联查询,比如说:select * from emp,dept where emp.deptno = dept.deptno .仔细想想,查询主要是对BLOCK的操作,查询的BLOCK越多,系统IO就消耗越大。如果我把这两个表的数据聚集在少量的BLOCK里,查询效率一定会提高不少。
比如我现在将值deptno=10的所有员工抽取出来,并且把对应的部门信息也存储在这个BLOCK里(如果存不下了,可以为原来的块串联另外的块)。这就是索引聚簇表的工作原理。
二:创建过程。
索引聚簇表是基于一个索引聚簇(index cluster)创建的。里面记录的是各个聚簇键。聚簇键和我们用得做多的索引键不一样,索引键指向的是一行数据,聚簇键指向的是一个ORACLE BLOCK。我们可以先通过以下命令创建一个索引簇。
SQL> conn scott/tiger
已连接。
SQL> desc dept
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
SQL> create cluster emp_dept_cluster
2 ( deptno number(2) )
3 size 1024
4 /
簇已创建。
这个名字可以用户定义,不一定叫deptno,数据类型必须和需要使用这个聚簇的数据类型一致NUMBER(2)。在这里最关键的一个参数是size。这个选项原来告诉Oracle:我们希望与每个聚簇键值关联大约1024字节的数据(1024对于一般的表一条数据没问题),Oracle会在用这个数据库块上设置来计算每个块最 多能放下多少个聚簇键。假设块大小为8KB,Oracle会在每个数据库块上放上最多7个聚簇键,也就是说,对应部门10、20、30、40、50、60和70的数据会放在一个块上,一旦插入部门80,就会使用一个新块。存放的数据是和插入顺序相关的。
因 此,SIZE测试控制着每块上聚簇键的最大个数。这是对聚簇空间利用率影响最大的因素。如果把这个SIZE设置得太高,那么每个块上的键就会很少(单位BLOCK可以存的聚簇键就少了),我们会不必要地使用更多的空间。如果设置得太低,又会导致数据过分串链(一个聚簇键不够存放一条数据),这又与聚簇本来的目的不符,因为聚簇原本是为了把所有相关数据都存储在一个块上。
向聚簇中放数据之前,需要先对聚簇建立索引。可以现在就在聚簇中创建表,但是由于我们想同时创建和填充表,而有数据之前必须有一个聚簇索引,所以我们先来建立聚簇索引。
聚簇索引的任务是拿到一个聚簇键值,然后返回包含这个键的块的块地址。实际上这是一个主键,其中每个聚簇键值指向 聚簇本身中的一个块。因此,我们请求部门10的数据时,Oracle会读取聚簇键,确定相应的块地址,然后读取数据。聚簇键索引如下创建:
SQL> create index emp_dept_cluster_idx
2 on cluster emp_dept_cluster
3 /
索引已创建。
现在可以创建表了:
SQL> conn segment_study/liugao
已连接。
SQL> create table dept
2 ( deptno number(2) primary key, 3 dname varchar2(14),
4 loc varchar2(13)
5 )
6 cluster emp_dept_cluster(deptno)
7 /
表已创建。
SQL> create table emp
2 ( empno number primary key,
3 ename varchar2(10),
4 job varchar2(9),
5 mgr number,
6 hiredate date,
7 sal number,
8 comm number,
9 deptno number(2) constraint emp_fk references dept(deptno)
10 )
11 cluster emp_dept_cluster(deptno)
12 /
表已创建。
我们可以通过一下SQL语句查看创建:
SQL> select cluster_name, table_name
2 from user_tables
3 where cluster_name is not null
4 order by 1;
CLUSTER_NAME TABLE_NAME
------------------------------ -----------------------------
EMP_DEPT_CLUSTER DEPT
EMP_DEPT_CLUSTER EMP
现在,聚簇,聚簇索引,聚簇索引表都已经建立完成
三:加载数据。
向聚簇索引表中加载数据是个很讲究的事情,处理方法不对,会使得聚簇的功能发挥不完全,降低查询性能。
方法1:
首先,我增加一个很大的列char(1000),加这个列是为了让EMP行远远大于现在的大小。使得一个1024的聚簇无法存储一行记录。不能加varchar2(1000),因为ORACLE对varchar2存储的原则是能省就省,如果数据数据不到1000,不会分配1000的空间的。char则是有多少用多少。呵呵。
SQL> begin
2 for x in ( select * from scott.dept )
3 loop
4 insert into dept
5 values ( x.deptno, x.dname, x.loc );
6 insert into emp
7 select *
8 from scott.emp
9 where deptno = x.deptno;
10 end loop;
11 end;
12 /
begin
*
第1行出现错误:
ORA-02032:聚簇表无法在簇索引建立之前使用
ORA-06512:在line 4
SQL> create index emp_dept_cluster_idx
2 on cluster emp_dept_cluster
3 ;
索引已创建。
SQL> alter table emp disable constraint emp_fk;
表已更改。
SQL> truncate cluster emp_dept_cluster;
簇已截断。
SQL> alter table emp enable constraint emp_fk;
表已更改。
SQL> alter table emp add data char(1000);
表已更改。
新闻热点




疑难解答