sql*plus: release 9.2.0.5.0 - production on 星期三 12月 1 23:56:32 2004
copyright (c) 1982, 2002, oracle corporation. all rights reserved.
连接到:
oracle9i enterprise edition release 9.2.0.5.0 - production
with the partitioning, olap and oracle data mining options
jserver release 9.2.0.5.0 - production
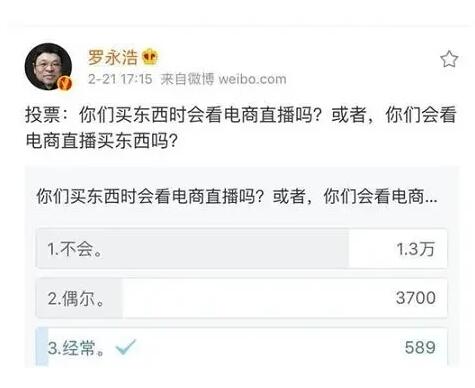
sql> grant execute on dbms_lock to kamus;
授权成功。
然后用kamus用户登录数据库,创建我们测试使用的存储过程sp_test_next_date。
create or replace procedure sp_test_next_date as p_jobno number; p_nextdate date; begin --将调用此存储过程的job的next_date设置为30分钟以后 select job into p_jobno from user_jobs where what = 'sp_test_next_date;'; execute immediate 'begin dbms_job.next_date(' || to_char(p_jobno) || ',sysdate+1/48);commit;end;'; --修改完毕以后检查user_jobs视图,输出job目前的next_date select next_date into p_nextdate from user_jobs where what = 'sp_test_next_date;'; dbms_output.put_line('job执行中的next_date: ' || to_char(p_nextdate,'yyyy-mm-dd hh24:mi:ss')); --等待10秒再退出执行 dbms_lock.sleep(seconds => 10); end sp_test_next_date;