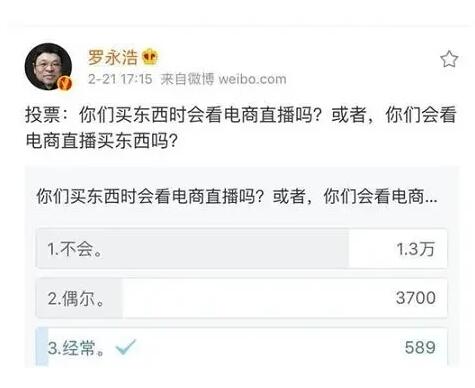
首页| 新闻| 科技| 人物| 科学| 话题| 运营| 设计| 开发| 服务器| 学院| 产品| 网文| 娱乐| 游戏| 图片
怎样用企业邮箱更能保障企业信
个人邮箱与企业邮箱有什么区别
怎样用企业邮箱更能保障企业信息安全?
校园甜美的背影,洋溢着青春烂漫的回忆
南国有佳人,容华若桃李
春天的魅力:绿杨烟外晓寒轻
春节临近,各地春节彩灯高高挂
路边摊小吃 酒香不怕巷子深
特色路边摊小吃 下班路上的一道美食
爷爷都是从孙子走过来的
我太帅了,睡不着咋整啊
新闻热点
疑难解答
图片精选
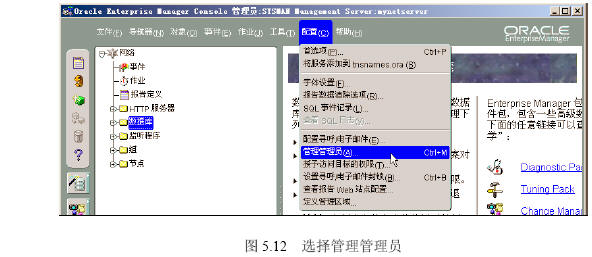
Oracle 9i如何管理【管理服务器】
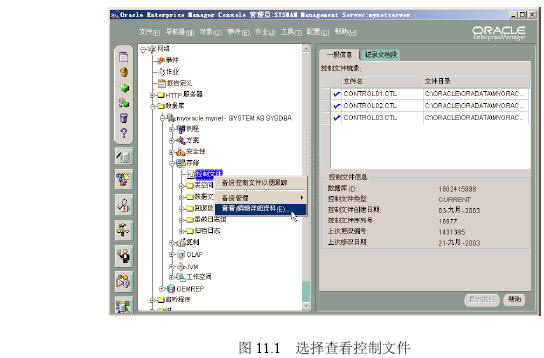
存储管理——深入Oracle 9i核心
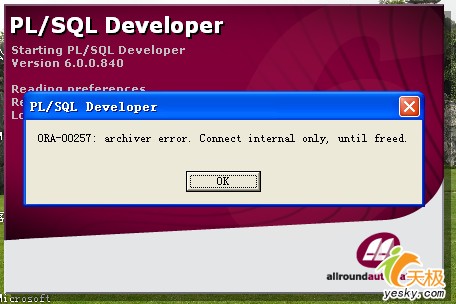
Oracle数据库的ORA-00257故障解决
新手入门 Windows下Oracle安装图解
网友关注