首页| 新闻| 科技| 人物| 科学| 话题| 运营| 设计| 开发| 服务器| 学院| 产品| 网文| 娱乐| 游戏| 图片
什么是SSL证书?网站为什么需要S
网站常见问题汇总
web用户控件调用.aspx页面里的方法
校园甜美的背影,洋溢着青春烂漫的回忆
南国有佳人,容华若桃李
春天的魅力:绿杨烟外晓寒轻
春节临近,各地春节彩灯高高挂
路边摊小吃 酒香不怕巷子深
特色路边摊小吃 下班路上的一道美食
爷爷都是从孙子走过来的
我太帅了,睡不着咋整啊
新闻热点
疑难解答
图片精选
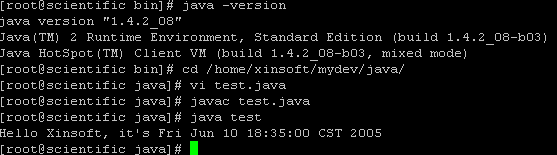
Linux下JSP运行、开发环境的建立
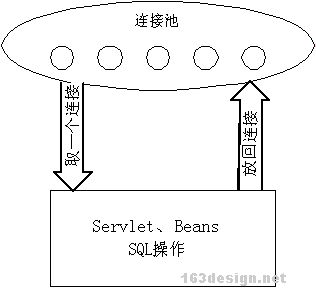
JSP数据库连接池的必要性
用JSP调用以Web应用形式部署在Tomc
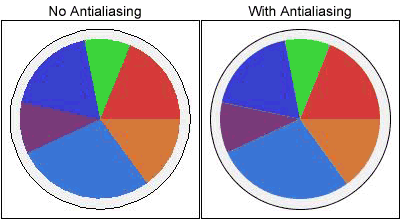
在JSP页面中轻松实现数据饼图
网友关注