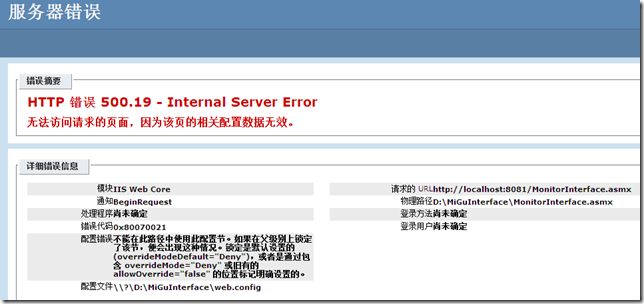
所有ELK的安装包都可以去官网下载,虽然速度稍慢,但还可以接受,官网地址:https://www.elastic.co/
logstash
在Logstash1.5.1版本,pattern的目录已经发生改变,存储在/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-0.1.10/目录下,但是好在配置引用的时候是可以对patterns的目录进行配置的,所以本人在Logstash的根目录下新建了一个patterns目录。而配置目录在1.5.1版本中也不存在了,如果是rpm包安装的,可以在/etc/logstash/conf.d/下面进行配置,但个人测试多次,这样启动经常性的失败,目前还没有去分析原因(个人不推荐使用RPM包安装)。所以大家可以采用Nohup或者screen的方式进行启动
专属nginx的pattern配置:
复制代码 代码如下:
NGINXACCESS %{IP:client} %{USER:ident} %{USER:auth} /[%{HTTPDATE:timestamp}/] /"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)/" %{HOST:domain} %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:useragent} "(%{IP:x_forwarder_for}|-)"
由于是测试环境,我这里使用logstash读取nginx日志文件的方式来获取nginx的日志,并且仅读取了nginx的access log,对于error log没有关心。
使用的logstash版本为2.2.0,在log stash程序目录下创建conf文件夹,用于存放解析日志的配置文件,并在其中创建文件test.conf,文件内容如下:
input { file { path => ["/var/log/nginx/access.log"] }}filter { grok { match => { "message" => "%{IPORHOST:clientip} /[%{HTTPDATE:time}/] /"%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}/" %{NUMBER:http_status_code} %{NUMBER:bytes} /"(?<http_referer>/S+)/" /"(?<http_user_agent>/S+)/" /"(?<http_x_forwarded_for>/S+)/"" } } }output { elasticsearch { hosts => ["10.103.17.4:9200"] index => "logstash-nginx-test-%{+YYYY.MM.dd}" workers => 1 flush_size => 1 idle_flush_time => 1 template_overwrite => true } stdout{codec => rubydebug}} 需要说明的是,filter字段中的grok部分,由于nginx的日志是格式化的,logstash解析日志的思路为通过正则表达式来匹配日志,并将字段保存到相应的变量中。logstash中使用grok插件来解析日志,grok中message部分为对应的grok语法,并不完全等价于正则表达式的语法,在其中增加了变量信息。
具体grok语法不作过多介绍,可以通过logstash的官方文档中来了解。但grok语法中的变量类型如IPORHOST并未找到具体的文档,只能通过在logstash的安装目录下通过grep -nr "IPORHOST" .来搜索具体的含义。
配置文件中的stdout部分用于打印grok解析结果的信息,在调试阶段一定要打开。
可以通过这里来验证grok表达式的语法是否正确,编写grok表达式的时候可以在这里编写和测试。
对于elasticsearch部分不做过多介绍,网上容易找到资料。
elk收集分析nginx access日志
使用redis的push和pop做队列,然后有个logstash_indexer来从队列中pop数据分析插入elasticsearch。这样做的好处是可扩展,logstash_agent只需要收集log进入队列即可,比较可能会有瓶颈的log分析使用logstash_indexer来做,而这个logstash_indexer又是可以水平扩展的,我可以在单独的机器上跑多个indexer来进行日志分析存储。
新闻热点





疑难解答