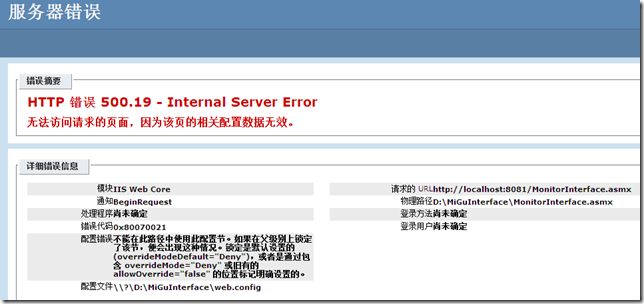
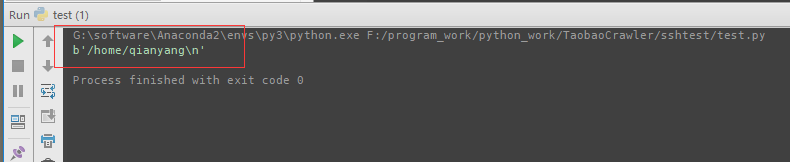
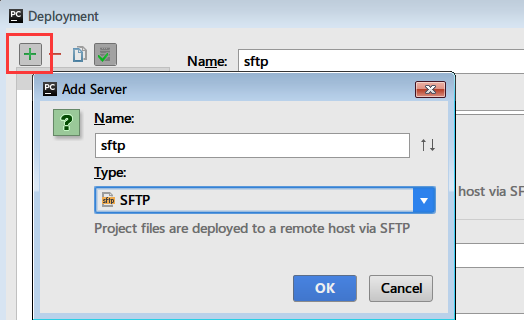
python2中的urllib2改为python3中的urllib.request
四种方式对比:
python2的get
# coding=utf-8import urllibimport urllib2word = urllib.urlencode({"wd":"百度"})url = 'http://www.baidu.com/s' + '?' + wordrequest = urllib2.Request(url)print urllib2.urlopen(request).read().decode('utf-8')python3的get
import urllib.requestimport urllib.parsedata = urllib.parse.urlencode({'wd':'百度'})url = 'http://wwww.baidu.com/s?' + data# url = 'http://www.baidu.com/s?wd=' + urllib.parse.quote('百度')response = urllib.request.urlopen(url)print (response.read().decode('utf-8'))python2的post
# coding=utf-8import urllibimport urllib2formdata = { 'name':'百度'}data = urllib.urlencode(formdata)request = urllib2.Request(url = "http://httpbin.org/post", data=data)response = urllib2.urlopen(request)print response.read()python3的post
import urllib.parseimport urllib.requestdata = bytes(urllib.parse.urlencode({'name':'百度'}),encoding='utf8')response = urllib.request.urlopen('http://httpbin.org/post',data=data)print(response.read().decode('utf-8'))或
import urllib.parseimport urllib.requestrequest = urllib.request.Request('http://httpbin.org/post',data=bytes(urllib.parse.urlencode({'name':'百度'}),encoding='utf8))'))response = urllib.request.urlopen(request)print (response.read().decode('utf-8'))以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持错新网之家。
新闻热点





疑难解答