hash、chunkhash、contenthash
hash一般是结合CDN缓存来使用,通过webpack构建之后,生成对应文件名自动带上对应的MD5值。如果文件内容改变的话,那么对应文件哈希值也会改变,对应的HTML引用的URL地址也会改变,触发CDN服务器从源服务器上拉取对应数据,进而更新本地缓存。但是在实际使用的时候,这几种hash计算还是有一定区别。
我们先建一个测试案例来模拟下:
项目结构
我们的项目结构很简单,入口文件index.js,引用了index.css。然后新建了jquery.js和test.js作为公共库。
//index.js require('./index.css') module.exports = function(){ console.log(`I'm jack`) var a = 12 }//index.css .selected : { display: flex; transition: all .6s; user-select: none; background: linear-gradient(to bottom, white, black); }接着我们修改webpack.config.js来模拟不同hash计算
hash
hash是跟整个项目的构建相关,只要项目里有文件更改,整个项目构建的hash值都会更改,并且全部文件都共用相同的hash值
var extractTextPlugin = require('extract-text-webpack-plugin'), path = require('path') module.exports = { context : path.join(__dirname,'src'), entry:{ main: './index.js', vender:['./jquery.js','./test.js'] }, module:{ rules:[{ test://.css$/, use: extractTextPlugin.extract({ fallback:'style-loader', use:'css-loader' }) }] }, output:{ path:path.join(__dirname, '/dist/js'), filename: 'bundle.[name].[hash].js', }, plugins:[ new extractTextPlugin('../css/bundle.[name].[hash].css') ] }根据上面的配置,我们执行webpack命令之后,可以得到下面的结果
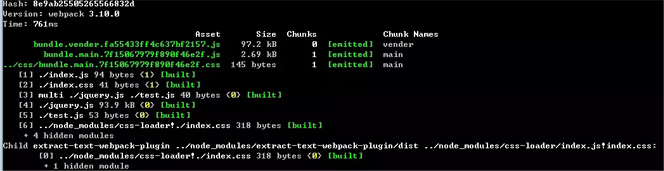
采用hash计算的执行结果1:
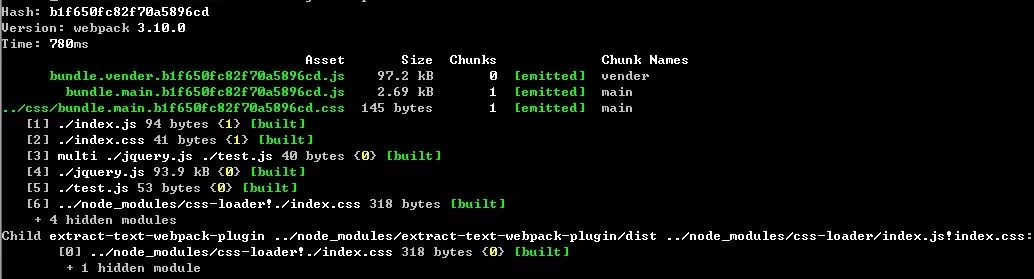
执行结果2:
我们可以看到构建生成的文件hash值都是一样的,所以hash计算是跟整个项目的构建相关,同一次构建过程中生成的哈希都是一样的
chunkhash
采用hash计算的话,每一次构建后生成的哈希值都不一样,即使文件内容压根没有改变。这样子是没办法实现缓存效果,我们需要换另一种哈希值计算方式,即chunkhash。
chunkhash和hash不一样,它根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk,生成对应的哈希值。我们在生产环境里把一些公共库和程序入口文件区分开,单独打包构建,接着我们采用chunkhash的方式生成哈希值,那么只要我们不改动公共库的代码,就可以保证其哈希值不会受影响。
var extractTextPlugin = require('extract-text-webpack-plugin'), path = require('path') module.exports = { ... ... output:{ path:path.join(__dirname, '/dist/js'), filename: 'bundle.[name].[chunkhash].js', }, plugins:[ new extractTextPlugin('../css/bundle.[name].[chunkhash].css') ] }采用chunkhash计算的执行结果1:
执行结果2:

新闻热点





疑难解答