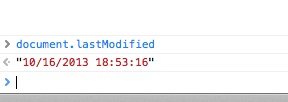
Byte-Order Mark found in UTF-8 File. The Unicode Byte-Order Mark (BOM) in UTF-8 encoded files is known to cause problems for some text editors and older browsers. You may want to consider avoiding its use until it is better supported.
XHTML验证某网站时,出现了以上的"错误",原来是Byte-Order Mark found in UTF-8 File这个问题。 即:在以utf-8编码的文件出现有BOM标记